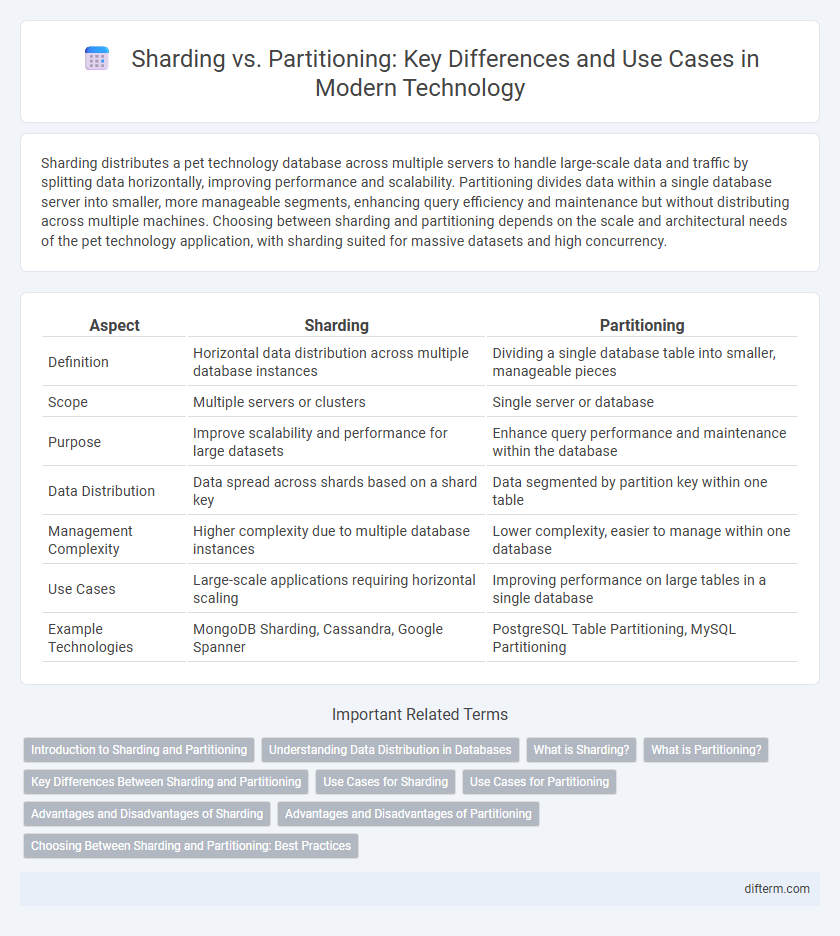
Sharding distributes a pet technology database across multiple servers to handle large-scale data and traffic by splitting data horizontally, improving performance and scalability. Partitioning divides data within a single database server into smaller, more manageable segments, enhancing query efficiency and maintenance but without distributing across multiple machines. Choosing between sharding and partitioning depends on the scale and architectural needs of the pet technology application, with sharding suited for massive datasets and high concurrency.
Table of Comparison
| Aspect | Sharding | Partitioning |
|---|---|---|
| Definition | Horizontal data distribution across multiple database instances | Dividing a single database table into smaller, manageable pieces |
| Scope | Multiple servers or clusters | Single server or database |
| Purpose | Improve scalability and performance for large datasets | Enhance query performance and maintenance within the database |
| Data Distribution | Data spread across shards based on a shard key | Data segmented by partition key within one table |
| Management Complexity | Higher complexity due to multiple database instances | Lower complexity, easier to manage within one database |
| Use Cases | Large-scale applications requiring horizontal scaling | Improving performance on large tables in a single database |
| Example Technologies | MongoDB Sharding, Cassandra, Google Spanner | PostgreSQL Table Partitioning, MySQL Partitioning |
Introduction to Sharding and Partitioning
Sharding and partitioning are database optimization techniques that divide large datasets into smaller, manageable segments for improved performance and scalability. Sharding distributes data horizontally across multiple servers based on a shard key, enabling parallel processing and reducing query load on single nodes. Partitioning organizes data within a single database into distinct parts, enhancing query efficiency and maintenance without distributing data across different machines.
Understanding Data Distribution in Databases
Sharding and partitioning both distribute data across multiple storage units but serve different purposes in database management. Sharding horizontally splits a database into smaller, independent shards that can be distributed across different servers to enhance scalability and performance, primarily used in large-scale distributed systems. Partitioning divides a single database into distinct segments within the same server or cluster to improve query efficiency and maintainability without necessarily providing horizontal scalability.
What is Sharding?
Sharding is a database architecture technique that horizontally partitions data across multiple servers or nodes to improve performance and scalability. Each shard contains a subset of the total data, allowing parallel processing and reducing query load on individual databases. This approach is widely used in distributed systems, big data applications, and cloud-based services to efficiently handle massive datasets and high throughput.
What is Partitioning?
Partitioning refers to dividing a database into distinct, smaller segments called partitions, each stored and managed separately to enhance performance and manageability. It improves query efficiency by limiting data scans to relevant partitions, supports scalability by distributing data across multiple disks or nodes, and simplifies maintenance tasks such as backups and archiving. Common partitioning strategies include range, list, and hash partitioning, each tailored to specific data distribution needs and access patterns.
Key Differences Between Sharding and Partitioning
Sharding distributes data across multiple physical databases to enhance horizontal scalability, while partitioning divides data within a single database for improved manageability and query performance. Sharding often involves complex routing logic to direct queries to the appropriate shard, whereas partitioning typically relies on database-level logic to handle data segmentation transparently. Unlike partitioning, sharding supports distributed systems and is essential for handling massive datasets in cloud environments.
Use Cases for Sharding
Sharding is ideal for large-scale distributed databases requiring horizontal scaling and high availability, commonly used in applications like social media platforms, online gaming, and large e-commerce sites. It enables efficient management of massive datasets by distributing data across multiple servers, reducing latency and improving query performance. Use cases also include real-time analytics and multi-tenant SaaS applications where workload isolation and fault tolerance are critical.
Use Cases for Partitioning
Partitioning is highly effective for improving database performance and scalability by dividing large datasets into smaller, manageable segments based on specific keys such as date, region, or customer ID. It is commonly used in transactional systems, data warehousing, and online analytical processing (OLAP) where queries target specific partitions to reduce I/O and speed up response times. Enterprises handling time-series data, multi-tenant applications, or geographically distributed data benefit from partitioning as it simplifies maintenance and enhances parallel processing capabilities.
Advantages and Disadvantages of Sharding
Sharding enables horizontal scaling by distributing data across multiple database instances, which significantly improves query performance and reduces latency in large-scale applications. However, it introduces complexity in terms of data management, consistency, and cross-shard transactions, often requiring sophisticated coordination mechanisms. The trade-off between enhanced scalability and operational overhead must be carefully considered in the context of system architecture and workload patterns.
Advantages and Disadvantages of Partitioning
Partitioning enhances database performance by dividing large datasets into smaller, more manageable segments, enabling faster query response and improved maintenance. A key advantage is improved scalability and easier data management, but partitioning can introduce complexity in query optimization and may lead to uneven data distribution causing hotspots. It is essential to carefully design partitioning strategies to balance load and minimize potential performance bottlenecks.
Choosing Between Sharding and Partitioning: Best Practices
Choosing between sharding and partitioning depends on data volume and application scalability requirements. Sharding distributes data across multiple servers to handle large-scale, high-traffic databases, enhancing horizontal scaling and fault tolerance. Partitioning divides data within a single database for performance optimization and maintenance simplicity, suitable for moderate data sizes and less complex querying needs.
Sharding vs Partitioning Infographic